スーファミと私
ブログシステムの構築からまた横道にそれはじめている。「ボカロ(作るところから)はじめました」を読んでちょっとスーファミ音源に興味を持ったので、細かく技術的なところを追っていこうと思いこのエントリを書いた。おそらくこのボリュームくらいのものを数回書かなければ全貌は理解できないのでないかと思う。というか今回はちょっと横道にはずれているところが多いからもうちょっと短くできるかもしれないけども。

私は3年ほどゲーム会社にいたのだけれども、ちょうど2社目の会社を辞めるか辞めないかのときにちょうどこのスーファミのことがその会社でも話題になっていた。今までのFCの開発システムは使えず、任天堂から提供される開発システムを購入しなければならずさらにその開発システムが非常に高価であるとか、UNIXの知識が必要で敷居が高いとかそんな話を上司から聞いた。
当時FCの開発システムはPC98 + ICEという構成で、ソフトウェアはエディタ(MIFES)と6502のアセンブラ(ファミコンのCPUは6502ベースだけれどもひょっとするとマシンコードが違うかもしれないからカスタマイズされているかも)というMS-DOSベースのシステムだった。MS-DOSに慣れ親しんでいるFC開発チームにとってはUNIXなど触ったこともないし、教育コストもかなりかかりそうだということだった。
私は当時アーケード(ゲームセンター)用の開発と、音源の演奏プログラムを担当しており、開発はHP64000システムで行っていた。これはICE・ROMライタと開発に必要なソフトウェア(エディタ・アセンブラ)、さらには外付けHDD(これが各端末と共有だったように思う)を備えていたオールインワン・パッケージであった。 その前に勤めていた会社ではHP9000というHP-UXのワークステーションもあったけれども、エディタやアセンブラがHP64000と違っていて使いづらかったから利用は極力避けていたので知らないも同然だった。そういうわけで私にとってもSFCはちょっと敷居が高そうだと思っていた。
当時の会社としてはハドソン/NECのPCエンジンも勢いがあったのでそっちに軸足を移すという選択肢もあったので新たなSFCへの投資は否定的な感じであった。実際私が辞めた後この会社はPCエンジンに軸足を移し、ヒット作を出したけれど2000年代に消滅してしまった。おそらくこの時のSFCへの対応の遅れも遠因だったのではないだろうか。
横道にそれたが、私は結局SFCの音源をいじることはなかった。けれどそのスペックの高さは話題になっていたので雑誌等で情報を得ることはできた。それまでのFC音源はPSGに毛が生えたようなもでしかなくて、コナミなんかは限界を感じてカセット側に音源を持たせたりしていたよね。それでもPSGに比べFCの音源は波形が三角波が出せたり、矩形波はデューティー比が変えられたりと音色の変化幅はPSGとは比較にならないのだが。当時のアーケード(ゲーセン)のゲームの音源はFM音源+サンプリング音源2-4CH位であったと思う。石のスペックはメーカーによって結構ばらつきがあった。
私が勤めていた会社ではYM-2151、YM-3526、YM-3812が多かった。サンプリング音源はメーカーオリジナルであったと思う。波形メモリ音源はもう下火になっており、PCエンジンが使っているくらいだったと思う。ただPCエンジンの波形メモリ音源は私にとっては非常に魅力的でこの音源ドライバの改良は積極的に取り組んでいたように思う。ガンヘッドのBGMはドラムがサンプリングでどうにかしてPCエンジンの波形メモリにサンプルデータ流し込んでいると思われたのでいろいろトライしようとしていたところで会社自体を辞めてしまったけれどもね。
私はあんまりスーファミで遊んでないんだけれども、「スーパードンキーコング」はハマった。ゲームももちろんだけれどもその音楽にも。
サンプルのドラムとかベースの枯れ具合がなんとも好きであった。
SFCの音源
で、本題のSFCの音源はそういう時代に誕生した8CHサンプリング音源である。仕様は以下のとおりである。| 項目 | 内容 |
|---|---|
| サンプリング周波数 | 32KHz |
| SRAM | 64kb |
| 同時発音数 | 8チャンネル |
| 標本化方式 | 16bit ステレオ ( ADPCM ) |
| CPU | SPC700 クロック周波数(2.048MHz) 6502互換 |
| DSPの機能 | |
| BRRデコーダ | BRR圧縮された波形データの復元 |
| ADSR | エンベロープジェネレータ |
| ガウス分布補間 | 表引きによる曲線近似 |
| ディレイ | 最大240ms |
| リバーブ | 残響成分のシミュレート。次数8のFIRフィルタ付(一般的なリバーブのLPF/HPFに相当) |
| ピッチモジュレーション | 1チャンネルのみ不可 |
| ノイズ | 発生周波数: 0~32kHz |
| ピッチベンド |
DPCM
BRRフォーマットを理解するためにはADPCMを、ADPCMを理解するにはDPCMを理解しておかねばならないので勉強することにする。 DPCM(Differential Pulse Code Modulation)というのは連続した音データの相関性に着目し「符号を1つ前のサンプルからの差分データで表し、情報量を削減する」というものである。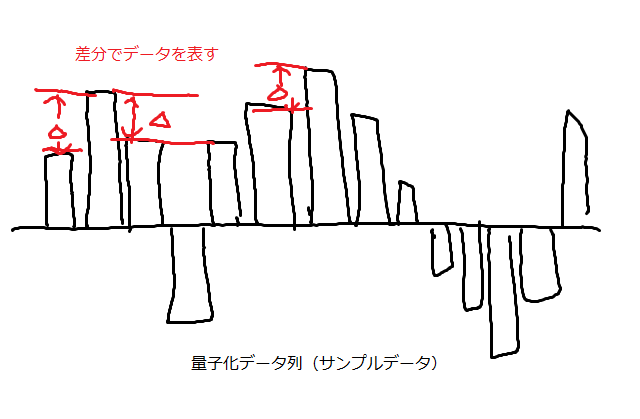 符号は例えば8ビット PCMデータであれば4ビット以下にする。そうすると情報量を半分以下に抑えることができる。 ただし8ビット量子化値を4ビットの符号で表そうとすると、差分は-7~7の間に収めなければならないが必ずしもそうはならないので、その場合は差分を最大値・最小値に丸める。よって実際の量子化データとは差異が発生するので音質が悪くなり、これがよくも悪くも「クセ」を生む原因となる。音質もさることながらもっと問題なのはその誤差によって波形の再現性が著しく損なわれてしまうことである。ウィキペディアの「差分パルス符号変調」によれば、
符号は例えば8ビット PCMデータであれば4ビット以下にする。そうすると情報量を半分以下に抑えることができる。 ただし8ビット量子化値を4ビットの符号で表そうとすると、差分は-7~7の間に収めなければならないが必ずしもそうはならないので、その場合は差分を最大値・最小値に丸める。よって実際の量子化データとは差異が発生するので音質が悪くなり、これがよくも悪くも「クセ」を生む原因となる。音質もさることながらもっと問題なのはその誤差によって波形の再現性が著しく損なわれてしまうことである。ウィキペディアの「差分パルス符号変調」によれば、
2.の方式で行うと誤差が少なくなるとのこと。 サンプルデータをDPCMの2つの方法で量子化した結果をグラフ化してみる。これはもう一目瞭然だろう。2.の方法が誤差が少ない。 しかし2.の方法をもってしても、音質的にはかなり落ちる。もう少しグラフを細かい単位でみるとそれはわかる。 大きい変化に追随できない点がDPCMの欠点である。差分PCM の入力はアナログ、デジタルのいずれでもよい。時間的に連続したアナログ信号の場合は最初に標本化が行われ離散的な信号に変換される。その後の処理は以下の2つの方法が考えられる。 1. 連続する標本値の差をとった後に量子化を行う。 2. 連続する標本値の差の代わりに、過去の符号化データからデコードした値と標本値との差の量子化を行う。 最初の方法は量子化の際の誤差が蓄積されていく問題があり、差分PCMでは2番目の方法が使用される。デコードは受信した値を単純に加算していくことで行う。
ADPCM
続いてADPCMである。この存在を知ったのはMSX-AUDIOのころであった。X68000やFM-TOWNSでも採用されている。1980年後半~1990年前半のPCのサンプリング音源はADPCMがデファクトであったかもしれない。 ADPCMを調べると私は本質をあまり理解していないこともわかった。 OKI電気さんのサイトの声と音の技術 ADPCM音声符号化技術によると、- 量子化特性を振幅変化範囲の大きさに応じて適応的に変える量子化方法を『適応量子化』という。適応量子化では振幅範囲が大きい所では量子化幅を大きくして振幅変化に追随するようにし、振幅範囲が小さい所では量子化幅を小さくし、小さな信号変化を再現する。
- 適応量子化を用いた符号化(encode)の一つが、適応差分PCM(Adaptive Differential PCM:ADPCM)である。
- 予測値を0に初期化する。予測値とは差分値を足しこんだ(誤差を含んだ)復号化後の量子化値である。さらに量子化幅を1に初期化する。
- 符号化対象の量子化値から予測値を引き算し、差分値を得る。量子化値から予測値を引くのは誤差の蓄積を防ぐためである。
- 差分値の絶対値を量子化幅で割り算する。0以下になった場合は0とし、7以上となった場合は7とする。さらに差分値がマイナスであった場合は4ビット目に1をセットする。これを符号とする。
- 予測値を計算する。符号の0-3ビットを取り出し量子化幅をかけ、差分値を復号する。符号の4ビット目が1の場合は復号値にマイナス1をかける。復号値を現在の予測値に足し、次の予測値とする。
- 符号値を元に量子化幅を調整する。符号値から量子化幅適応化係数を求め(表引き)量子化幅に掛け、次の量子化幅とする。
ADPCM音声符号化技術より符号化値 量子化幅適応化係数 10進値 0111 2.4 7 0110 2.0 6 0101 1.6 5 0100 1.2 4 0011 0.9 3 0010 0.9 2 0001 0.9 1 0000 0.9 0 1111 0.9 -1 1110 0.9 -2 1101 0.9 -3 1100 0.9 -4 1011 1.2 -5 1010 1.6 -6 1001 2.0 -7 1000 2.4 -8 -
2.~5.を繰り返す
となる。5.がミソである。 元データ・DPCM・ADPCMと比較した結果は下の図のとおりである。
量子化幅が適切に調整されるので、DPCMよりもADPCMの方が波形の再現度が高いことがわかる。ただ「完全」ではないのでこの方式でも再生音は「クセ」のある音となる。
BRR形式
さてようやくBRRである。Bit Rate Reduction (BRR) in SNES Developmentに詳細に説明が載っているので、これを若干端折り気味に訳しつつ追記してみる。 BRR(Bit Rate Reduction)はSNESのSPC700サウンドチップによって使用される音声符号化スキームである。それは32:9の比率で圧縮され、32バイトごとの16ビットPCMデータは9バイトのBRR符号となる。これらの9バイトは次のように1バイトのヘッダと16ニブル(4ビット)のデータからなる。| byte 1 | byte 2 | byte 3 | ~ | byte 9 |
|---|---|---|---|---|
| header | data 1 : data 2 | data 3 : data 4 | ~ | data 15 : data 16 |
| bit 7-4 | bit 3-2 | bit 1 | bit 0 |
|---|---|---|---|
| Rangeビット | フィルタービット | ループビット | エンドビット |
エンドビット
エンドビットはサンプルの終端を表す。エンドビットの9バイトブロックはデータ部分の8バイトがすべて0クリアされている。エンドビットを検出したときは8バイトのデータを読んだあとに終了すべきである。ループビット
ループするかどうかを表す。ループするサンプルデータはすべてのブロックにビットが立っている。しかしループ開始・終端を検出する標準的な方法はない。フィルタビット
フィルタを指定する。フィルタの値によってデコード時に以下の値が与えられる。詳細は「デコードのアルゴリズム」で述べる。| フィルタビットの値 | フィルタ値1 | フィルタ値2 |
|---|---|---|
| 0 | 0 | 0 |
| 1 | 15 / 16 | 0 |
| 2 | 61 / 32 | 15/16 |
| 3 | 115 / 64 | 13/16 |
レンジビット
レンジはデータブロックの量子化幅を決めるための情報である。データブロックの二ブルをいくつシフトするかの値が入っている。2であれば2ビット左にシフトする。データニブルは符号あり4ビット値であるので、シフト時には符号ビットの取り扱いに注意する。0-12までが有効な数字である。 つまりBRR形式では量子化幅をヘッダに埋め込んでいる。二ブルごとに埋め込むのでは効率が悪いので、16ニブルごとにしているようである。おそらくこれは音声を分析・解析したうえでの結果なのだろう。デコードのアルゴリズムについて
Wikipediaの「Bit Rate Reduction - Wikipedia, the free encyclopedia」をそのまま翻訳するとかなりいい加減な訳で申し訳ない。ちょっとこのフィルタはどのような特性を持つのかいまいちイメージできていない。 フィルタのパラメータはIIRフィルタの予測係数ということらしい。IIRフィルタというのはデジタルフィルタの一種である。FIRという方式に比べてフィードバックを用いて少ないタップ数で急峻なフィルタ特性を得ることができる。残念ながら私は理屈が全く理解できていない。デジタルフィルタは仕組みは簡単だが理屈が難しい。 というわけでスーファミの音源はそれまでの音源とは比較にならないほど本格的で、いろいろな理屈を盛り込んで設計されている。なんか久夛良木さんらしいなーという雰囲気がする。全貌を理解するにはまだまだ調べなければならないことがたくさんあるのでしばらく続ける。フィルタ(f)とレンジ(r)とともにブロック中のニブル(n)は次の2次線形予測式を使用しPCMサンプルStに復号される。 St = 2r n + k1 st-1 - k2 st - 2 ここではSt-1とSt-2はそれぞれ最後の復号値、最後から2番目の復号値である。フィルタータイプ f は次の表を使用してIIR予測係数kに変換される。
フィルタf k1 k2 0 15/16 0 1 61/32 15/16 2 115/64 13/16 計算はすべて符号化16.16固定少数点で行われる。
各フィルタの説明:
- フィルタ0はrビットで量子化されたデータを復号する
- フィルタ1はrビットで量子化されたデータを復号したものと1つ前の復号値に15/16を乗じたものを加える
- フィルタ2-3はrビットで量子化されたデータを復号したものに1つ前、2つ前のサンプルを線形外挿したものを加える(k1,k2をそれぞれ乗じたものを足す)