
S.F.@SFPGMR
@tenpoku1000 ああ。。トライグラフですか。なるほど。。
S.F.@SFPGMR
@tenpoku1000 ああ。。トライグラフですか。なるほど。。
S.F.@SFPGMR
ちょっとブログへの投稿を再開しようかなと思ったらシステムが動かなくなってた。mdファイルの先頭にjson-ldでメタデータを置くヘンテコなフォーマットで記事を書くと、静的にページをレンダリング(amp-htmlと普通のhtml)してサーバにアップするというやつなのだが。
去年の5月ころからブログへの投稿をやめてTwitterのみにしたのだが、簡便でいいかなと思ったのだが後で見直したりするときにちょっと面倒だなと思ったりしたのである。
去年ちょっと見直そうと思って手を付けたのだけれども、オレオレ言語つくりのほうがおもしろいので改造半ばで放り出していたようだ。オレオレ言語のログもTogetterでまとめとけばいいかなと思ったけどやっぱりつぶやきをまとめただけではやっぱり整理しずらいというか。。
なのでちょっとnodeで書いたその仕組みを手直しして、ブログを復活しようかなと思ったわけである。ただその仕組みもampへの対応がちょっと甘くて、エラーが出てたりするのでそこも手直しが必要ではある。
でまあコードを見直すともののの見事に忘れているわけである。なんだこのヘンテコな仕組みは?なにこの変なコード?みたいに今なってる。。
なのでちょっとオレオレ言語つくりの研究をお休みしてブログシステムの手直しをしようと思う。
この仕組みについてはこのあたりにまとめてはあるようだ。
この仕組みに引っ越したのって2017年7月だったのか。もっと前かと思ってたが。それでも1年半くらいは経ってるのか。
仕組みとしてはこの絵の通りである。DBレスでコンテンツを作る。 https://t.co/yegXDo4R0P

たしか「コンテンツは可能な限り静的に作成する」というポリシーで作ってたと思うんだよな。例えばシンタックス・ハイライトなんかも、動的にではなく静的にレンダリングしてる。AMPに対応しやすくするためでもあるんだけど。。
それとgitやパッケージシステム(npm)についてももう少し勉強いかんような気も。ほんと表面的なことしか知らないし、深く知ればもうちょっとスマートに作れそうな気がするんだよねえ。
npmって最近セキュリティ強化されて、インストール時とかにsecurity警告が出るようになってたりするし、auditしてfixすることも可能なようになってる。古いパッケージの見直しとかもしないといけないかなあと思ったりも。。
S.F.@SFPGMR
ザクソンは見た目のインパクトがすごかったよな。当時。3Dだ!と思ったなあ。
ゲーム文化保存研究所さんのツイート: "『ザクソン』を通じて考えるクォータービューシューティングの世界 https://t.co/FbfzlAyO1Q"
S.F.@SFPGMR
GLSL ES 3.0の仕様書の「3.1 Logical Phases of Compilation」を昨日から読んでるわけなのですが。
khronos.org/registry/OpenG…
文法をPEGで書き直すために「9 Shading Language Grammar」のBNFをベースに始めたんだけど、ここだけの情報ではパーサを作ることはできないんだよね。
たとえばフィールドセレクタはBNFで書かれていない。
structの正確な構文も書かれていない。プリプロセッサについても書かれていない。これは別の仕様書の項にあってそれを参照するわけですな。
当初文字解析・トークン分割・プリプロセス・構文解析・AST作成を一気に一つのPEGで書ききることを考えてたんだけど、ちょっとそれって無理があるなあ、無駄が多いなあ。。と「3.1Logical Phases of Compilation」を読んで思い始めたわけである。
もともとオレオレ言語はオリジナルな構文を目指していた。そうなると文法を文書化したほうがいいだろうから、それならPEGでパーサを書いて文法書の代わりにしようかと考えた。
でいまいまの状態は一旦全部捨ててGLSLにできる限り忠実に実装しなおそうと思ってる。そうすると仕様はきっちりしたものがあるから、構文をPEGで書く意義は薄れてしまったわけですな。。
だがまあ過去にGLSLのパーサをPEG.jsで書いてる人がかなりいたりして、まあこの路線でもいいかなあと思ってたのだが、3.1を読むとそれもどうかなあと思い始めた。最初にここを読むべしであった。。
3.1 はコンパイルのフェーズが書いてあるんだけど、要点をまとめるこんな感じ
1.ソース文字列はバイト列。「0」は終端と解釈
2.ソース文字列は1つの入力として連結される
3.文字列はUTF-8
4.{CR,LF},{LF,CR}は1つの「new-line」文字に置換
(続く)
5.行番号はnew-lineの数+1。行番号は#lineディレクティブよってのみ変えることができ、6.の影響は受けない。
6.バックスラッシュ+new-lineは除去される。これによって改行をまたぐトークンの記述ができる。
7.コメントは1つのスペースに置換
(続く)
8.ソース文字列は「プリプロセス・トークン列」に変換される。トークン列は数字・識別子・プリプロセス操作(ディレクティブ?
)などが含まれる。行番号はトークンの先頭文字の行番号がコピーされる。
9.プリプロセッサが実行される。ディレクティブ は実行され、マクロ置換が実行される。
(続く)
10.空白とnew-lineは除去される。
11.前処理トークン列はトークン列に変換される
12.構文はGLSL ES 文法によって解析される
13.結果は言語のセマンティック規則によってチェックされる
(続く)
14.頂点およびフラグメントシェーダーは互いにリンクされる。頂点およびフラグメントシェーダーの両方で使用されない頂点出力および対応するフラグメント入力は破棄される。
15.バイナリが生成される。
3.1はコンパイル手順が簡潔に書いてあるわけなんですな。。
それでまあ「なるほど!」と思うと同時に、やっぱりなあ。。とも思ったんですな。
コンパイラを書いてるときにおぼろげながら思っていたことが、ここに簡潔に書いてあったというわけなのですよ。
さらに3.1の冒頭にはこんなことも書いてあったんですな。
「コンパイルプロセスはC++標準のサブセットを基本としている。」
ベースとしてるのはCではなくC++なんですな。。確かに変数宣言とかはCというよりはC++だもんな。。
プリプロセスっちゅうのはAST作る前に処理を終えておくのが基本なんだろうね。プリプロセス→AST生成を同時にPEGで書くって無理があるような。プリプロセスも含めたASTツリーを作ってASTベースでプリプロセスをやる感じにすればできそうだけど、なんかそれって無駄が多い感じがする。
バックスラッシュ+改行の処理などはプリプロセスの前に終えとかなくてはいかんしな。
プリプロセスの前処理だからプリプリプロセスですな。。
コメントの除去とかトークン分割とかまではできそうだから、PEG.jsでそこだけを処理するコードを書いたんですな。
sgl2/sgl2-0.pegjs at 0904f71ee9997ba496f0c1e120793a548d205908 · sfpgmr/sgl2 · GitHub
TDOPパーサをベースとした言語を作っていく. Contribute to sfpgmr/sgl2 development by creating an account on GitHub.
でこれ使うとトークンの配列が出力となって出てくる。コメントとかは3.1のルールに沿って置換される。でこれをプリプロセスしてまた文字列にしてPEGで作ったGLSLのパーサにまた食わせるというのもなんだかなあ。。と今思ってるわけ。PEGは入力が文字列だからね。なんか無駄だなあと。
ここから先はpratt parserの出番かなと。さらにPEGを使ってきて、デバッグの面倒さに嫌気も指してきているという。まさにTDOPの論文の冒頭に書いてあったことが今まさに起こっているのだ。。
この辺かな。。
PEG.jsでアクションを書いてくと、バックトラックによってそれまでのアクションが全部破棄されてしまうところもちょっとなあ。。と思ったんだよね。解析のトレースを見てると「うわーここまで作ったものが全部捨てられる。。」。それが特徴でいいところでもあるんだけど。
そしてまた別の構文をトライするところで破棄された構文のアクションで作成されたのと同じようなオブジェクトがまた作られて、それがマッチしなかったら破棄されて。。が、構文がマッチするまで繰り返されるわけだ。無駄なガベージ・コレクトが多発しそうな感じがしてなんともね。。
この辺の動きについてはPEGはそもそもリソースの潤沢な現代の環境での利用を想定してるようだから、まあいいっちゃあいいんだけどね。処理のムダはかなり発生してるのは事実っちゃあ事実だわな。。
これは解析速度の低下にもつながるんだろうけど、これを改善するために「メモ化」というアプローチも取られるらしいね。。Packrat Parserとかいうらしい。
あとパーサのソースコードが巨大になってしまうというのちょっと。。PEGは私の好みには合わないなあというのが今のところの感想。字句解析も一緒に書けるというのがメリットなんだけど、今回はそこだけ使わせてもらってあとは手書きパーサ(pratt parser)で書こうかなと思ってるのがいまいまの状況。
とはいえ私の好みに合わないというだけでPEG.jsがすごいライブラリであるというのは疑いのないところ。
と思ったら、pratt parserの内容すっかり忘れとる。。もう一回「ビューティフル・コード」読むかあ。。これがおっさんプログラマの悲しいところ。。物忘れの激しさは20代の2倍以上であると思われる。。
ちょっと考えて、以下のアプローチでいくことにしようかなといまいまはいこうと思ってる。
1.back slash(/) + new-line ('\n' or '\n\r' or '\r\n')を除去する
2.トークン分割
3.プリプロセス
4.パース
5.コード生成
1.をまずやってしまえば、2.以降はpegでやってしまえそうなこともないなあ。。
とりあえず1.,2.をpeg.jsで書いてみた。これを食わせるプリプロセッサをこれから書いてみようかなと思ってる。
プリプロセッサも結構面倒な感じ。。
仕様の3.5 Preprocessor を実装しようとしてるが、改めて気づくことが多いなあ。。
khronos.org/registry/OpenG…
まず、バージョン定義はプリプロセッサには含まれない。
#version number es
# の前にはスペースとタブのみ含むことができる。ディレクティブの終端は改行(New Line)である。プリプロセスはソース文字列の改行の相対位置・行番号を変更してはいけない。
プリプロセッサディレクティブは以下の通り
#
#define
#undef
#if
#ifdef
#ifndef
#else
#elif
#endif
#error
#pragma
#extension
#line
プリプロセッサ・オペレータは以下である
defined
#define と #undef 機能はパラメータあり・なしのマクロ定義については標準C++と同じである。
事前定義されているマクロは以下である。
__LINE__
__FILE__
__VERSION__
GL_ES
2つの連続したアンダースコアを含むマクロ名および、「GL_」がつく名前は予約されている。
マクロ名の長さは1024文字までである。
#if, #ifdef, #ifndef, #else, #elif, #endif は次を除いてC++と同じ。
1. #if , #elif に続く式はpp-constant-expressions のみに制限される
2.define オペレータで評価されない未定義の識別子は既定の'0'とみなされない。そのような識別子はエラーとなる。
3.文字定数は未サポート
pp-constant-expressionは、プリプロセス中に評価され、整数定数リテラルと以下の演算子から形成される整数式である。
( )
+
-
~
!
*
/
%
<<
>>
<
<=
>
>=
==
!=
&
^
|
&&
||
defined
GLSLのプリプロセッサはC++のサブセットなので、C++のプリプロセッサの仕様も読み始めた。ドラフトだと規格書が読めるからね。
プリプロセッサ自体もJSずっといじってるから忘れかけてるんだよなあ。なのでcodepadとかでコード書いて試してみたりしてる。
文字関係のマクロって面白いなあ。。GLSLのマクロでは使えんけど。。
#include "iostream"
#define join(a,c) # a # c
char p[] = join(x y z,c);
int main(){
std::cout << p << std::endl;
// x y zc
}
マクロを展開するとまたマクロが含まれる可能性があるから、マクロがなくなるまで再帰的に展開する必要があるんだよな。。
C++の規格(案)のプリプロセッサのところを年末の大掃除の合間に読んでた。プリプロセッサというのはなかなかおもろしいものだけど、実装するとなるとちょっと面倒なものだなあと思っていて。プリプロセッサの前処理用のトークナイザを書いてみたところでちょっと手が止まってしまってる。
プリプロセッサでこんなのできるんだなあ。。
#if VERSION == 1
#define INCFILE "vers1.h"
#elif VERSION == 2
#define INCFILE "vers2.h"
#else
#define INCFILE "versN.h"
#endif
#include INCFILE
同じケースだと、なんかこう書いてた気がするな。昔。。
#if VERSION == 1
#include "vers1.h"
#elif VERSION == 2
#include "vers2.h"
#else
#include "versN.h"
#endif
5.2 Phases of translation もよく読んどかんといかんわ。
結局C++の「5 Lexical conventions」全体をよく読んどかんといかんな。。
open-std.org/jtc1/sc22/wg21…
バックスラッシュ+改行を除く処理がどのフェーズで行われるか知りたかったんだけど、やっぱりプリプロセス処理(フェーズ4)の前(フェーズ2)でしたな。。
ちなみにC++の翻訳フェーズ(5.2 Phases of translation)は9段階あるそうだ。
1.物理ソース文字セットを基本文字セットに置き換える(基本文字に含まれない拡張文字をuniversal-character-nameに置き換える)
2.バックスラッシュ+改行を削除する(物理行→論理行への変換)
(続く)
3.プリプロセス・トークンと空白文字に分ける。コメントは1つの空白文字に置き換えられる。改行文字は維持される。
4.プリプロセスを実行する。プリプロセッサ・ディレクティブは削除される。
(続く)
5.文字リテラルと文字列リテラル中のエスケープシーケンスやuniversal-character-nameをexecution character setに変換する。
6.隣接文字列リテラルを連結する。
7.プリプロセス・トークンをトークンに変換する。空白文字は除去される。トークンは構文的・意味的に解析される。
(続く)
8.テンプレートのインスタンス化
9.外部参照の解決
プリプロセス・トークンに分割する前にバックスラッシュ+改行を削除するんだな。やっぱり。そうせんと分割する処理がややこしくなっちゃうもんね。。
続いて「5.3 Character sets」を読むとするか。
「universal-character-name」のBNFは以下の通り。
hex-quad:
hexadecimal-digit hexadecimal-digit hexadecimal-digit hexadecimal-digit
universal-character-name:
\u hex-quad
\U hex-quad hex-quad
utf-16 utf-32に対応してるのですな。。
いやいや、そういうことではないんだよなあ。。間違っとるわ。。文字コードと符号化方式をごちゃまぜにしてはいかんのですよ。。
Unicodeの闇にまた立ち入らんといかんな。。ああ、いやだ。。
\UNNNNNNNNはUCSのNNNNNNNNに対応する。Nは/0-9a-f/iですわ。。で\uNNNNはUCSの0000NNNNに対応するんですな。。ちなみに\Uは32ビット長あるけど実際は0 - 10FFFFの範囲に収まるということだよね。。
ん。ちょっと気になる一文が。。
If the hexadecimal value for a universal-character-name corresponds to a surrogate code point (in the range 0xD800–0xDFFF, inclusive),the program is ill-formed.
サロゲートコードポイントはill-formedなの??
そうするとサロゲート文字は使えんということか??と思ったが、ここでまた符号化方式と文字コードを混濁してしまう罠が。。そもそもサロゲートコードポイントってなんだ??
Unicodeってなんでこんなに罠だらけなんだろうな。。このコードにまつわる歴史がこのようなものにしてしまったんだよな。。
C++標準化委員会、ついに文字とは何かを理解する: char8_t - Qiita
サロゲート・コードポイントというのは、UTF-16という符号化方式で使われる。16ビットなので0xffff以上の文字コードはサロゲート・ペアで表すんだけど、それ用の接頭辞(プリフィクス)のようなものなのですな。
C++はコードポイントを直接\Uで指定できるから、サロゲート・コードポイントはいらんわけですわな。なのでサロゲート・コードポイントはill-formedにしてるということですわ。たぶん。
ちなみに\uは0000NNNNということで、上位16ビットが0で埋められるということで、UTF-16符号化方式であらわされる文字コードというわけではない。NNNNを超える場合は\Uにせいということなんだろうな。
「basic execution (wide-)character set」は基本ソース文字・制御文字(alert/バックススペース・CR・null文字(値は0)を含むのですな。
とここまで読んで、ソースコードの符号化方式に関する決め事がないことに気づいたような。。ここにきて「5.2 Phases of translation」の1.に書かれてあることが分かってきたような気がしないでもないという。
最初に読んだときなんのこっちゃよくわからんかったんだよね。。
GLSLだとソースコードの符号化方式を定めていたような気もしないでもないな。。GLSLの仕様を読み返すか。。
「3.2 Character Set」にばっちり「UTF-8」だと書いてあるわ。。
The source character set used for the OpenGL ES shading languages is Unicode in the UTF-8 encoding scheme.
ECMAScriptは「ソースキャラクタはUnicodeコードポイントである」ことだけが仕様で、符号化方式についての決まりごとはないようですな。。
C++の仕様(N4713)に戻り改めて読み返すと、実装で定義された作法で物理ソースファイルの文字を基本ソース文字セットにマッピングされると書いてある。物理ソースファイルとは「何らかの符号化方式でエンコードされたソースコードファイル」ということなんだろうな。。
それを実装依存で解釈し、基本ソース文字セットに変換すると。
文字セットというのが色々あってですな。。
・basic source character set
・basic execution character set
・execution character set
さらにワイド文字?ちゅうのもあるそうな。。
・basic source wide-character set
・basic execution wide-character set
・execution wide-character set
ようやく「5.4 Preprocessing tokens」に到達したな。。
C++ではトークン
1.プリプロセッシング・トークン
↓プリプロセス
2.トークン
の2種類あるんですな。ソースコードはプリプロセッシング・トークンに分割されたのちにプリプロセッサに投入され、プリプロセスでディレクティブやホワイトスペースが除去されてトークンとなるようである。
BNFはこうなってますな。。
preprocessing-token:
header-name
identifier
pp-number
character-literal
user-defined-character-literal
string-literal
user-defined-string-literal
preprocessing-op-or-punc
each non-white-space character that cannot be one of the above
BNFの項それぞれがpreprocessing-tokenのカテゴリでもあるわけだけども。
preprocessing-tokenはwhite-spaceもしくはcommentで区切ることができるんだな。white-spaceは「スペース・水平タブ・改行・垂直タブ・フォームフィード」文字のことですな。翻訳フェーズ4においてはトークンを分割する以上の意味を持つとのこと(これは改行文字のことかな。。)
preprocessing-tokenは翻訳フェーズの3から6における字句の最小単位である。
改行はプリプロセッサ・ディレクティブの文脈においてはディレクティブの終端をあらわす。ステートメントにおけるセミコロンのような役割ですな。なのでバックスラッシュ+改行というのがプリプロセスにおける改行のエスケープシーケンスとして効力を発揮するというわけ。
複数行のマクロ定義などがこれで可能になってるというわけですな。
ちょっとふつふつと疑問として湧き上がってることがあって。そもそもなぜプリプロセッサなるものが必要なのかなあ?という疑問。
ちょっとその疑問は置いておいて、「5.4 Preprocessing tokens」を読み進めますわ。。
GLSLから横道にそれてしまったが、GLSLのプリプロセッサがC++のサブセットであるということで仕様上の説明が簡略化されている以上、これを理解しないで前に進むことはできないのだ。
5.4の段落3を読んでてraw string literalなるものを発見?C++98の知識で止まってる私は知らないことだらけですな。。
ははあ。こういうやつかあ。。例を見て理解したわ。。
R"a(
)\
a"
)a"
は "\n)\\\na\"\n"という文字リテラルと等価とのこと。
JSでいうところのテンプレートリテラルみたいなものだなあ。。
C++11ってすげえなあ。。
raw string literalのBNF見るとこうなっとるな。。
raw-string:
" d-char-sequenceopt ( r-char-sequenceopt ) d-char-sequenceopt "
こういうことか。。
R "デリミタ名(オプション)(文字列)デリミタ名"
const char * c = R "(
"aaaaaa"
)";
試してみた。。
文字列リテラルのBNFはこうなっとる。。
string-literal:
encoding-prefixopt " s-char-sequenceopt "
encoding-prefixopt R raw-string
raw-sring-literalなんちゅうBNF上のキーワードがあるかと思ったがなかったな。。
「R」のprefixとダブルクォーテーションの間はスペース不可ですな。
なるほどお。
#include <iostream>
#include <cstdlib>
const char * a = R"cpp-beginner(
"aaaaaa"
)cpp-beginner";
int main()
{
std::cout << a << std::endl;
}
5.4.の3.1はraw string literalに関することが書いてあって
・preprocessing tokenに分割後、「R」にすぐ次に「"」がある場合はraw string literalとして処理する
・raw stringとみなされる部分の、翻訳フェーズ1および2において実施された変換は元に戻す
とのこと。もとに戻すんだ。。
raw string literalに対応するために、preprocessing tokenで追加の処理が発生するわけですな。。
GLSLは文字列リテラルないから理解する必要はないんだけど、オレオレ言語はGLSLのスーパーセットにするつもりで文字列に関する処理を追加しようと思ってるから、この辺の理解はきちんとしておこう。
プリプロッサの字句関連の処理って私のレベルだとちょっと難しそうなんで、実装できるかどうかは未知数だし、そもそも必要?というのはあるんだけど。
5.4.3.2は代替トークンのエスケープ表現のようですな。。トークンに続く3文字が<::かつ後に続く文字が:や>でもない場合は、最初の<は代替トークン「<:」としては扱われず、「<」として取り扱われるとのこと。
#define R "x"
const char* s = R"y";
// ill-formed raw string, not "x" "y"
// これは5.4.3のルールによってraw stringが先に検出されるので不正となる
#define R "x"
const char* s = R "y";
// Rと"の間にスペースを入れることによってRはマクロとして認識される。
5.4.4.はpreprocessing number tokenに関しての例
0xe+foo
は
0xe,+, fooとしてトークン分割可能だが、実際にはpreprocessing numberとして扱われる。結果このケースではエラーとなる。
0xe,+, fooとしてトークン分割したければスペースを挟む。
0xe +foo
同じように
1E1
はEがマクロ定義されてもされていなくても、preprocessing numberとして取り扱われる。結果数値として正しく取り扱われる。
5.4.5 は最長のtokenで分割されることの例
x+++++y
は
(1)x, ++, ++, +y
に分割される。これはエラーとなる
(2)x, ++, +, ++, y
こう分割されるとエラーとはならない。
が、5.4.3によりマッチする最長のpreprocessing tokenで分割されるので結果は(1)となる
次は「5.5 Alternative tokens」ですな。これはまあ斜め読みでいいかなあ。普通使わないし。。古いCソースとかコンパイルするために必要なんだろうな。。今でも「{」とか使えない環境があるのだろうか。。
ちなみにC++のドラフトってここにおいてあるみたいなんだよね。。
draft/papers at master · cplusplus/draft · GitHub
C++ standards drafts. Contribute to cplusplus/draft development by creating an account on GitHub.
まあこれくらいの理解OKかと。。 https://t.co/t9O8O8Hsdd

int main()
{
bool a = true,b = true;
if(a and b){// &&の代替表現。この方が直感的?
std::cout << "True" << std::endl;
}
}
「5.6 Tokens」はまあこれはわかるかあ。。
token:
identifier 識別子
keyword キーワード
literal リテラル
operator 演算子
punctuator 区切子
トークンは5種類あるということね。。ホワイトスペースはトークンの区切りを表す以外は無視される。
「5.7 Comment」 はスキップするかあ。。
次は「5.8 Header names」か。。
BNFは以下の通りですな。。
header-name:
< h-char-sequence >
" q-char-sequence "
h-char-sequenceのBNFは
h-char-sequence:
h-char
h-char-sequence h-char
h-char:
new-lineと>を除くソース・キャラクタ・セット
まあそりゃそうか。。
q-char-sequenceのBNFは
q-char-sequence:
q-char
q-char-sequence q-char
q-char:
new-lineと"を除くソース・キャラクタ・セット
これも別段理解に支障はないですな。。
さて、「5.9 Preprocessing numbers」ですな。。
数値リテラルはプリプロセスの前にトークン分割される。ただしプリプロセスの段階では型と値は持たないとのこと。
ただBNFの1行で気になるものが。。
pp-number identifier-nondigit
と思ったらこれはユーザー定義リテラルですな。。
さて次は「5.10 Identifiers」ですかな。。
C++では識別子の長さは任意となっているな。GLSLでは1024文字と規定されてる。
universal-character-nameで変数名も定義できるんですな。
#include <iostream>
#include <cstdlib>
int main()
{
int \u3042 = 1;//「あ」
std::cout << "\u3042:" << \u3042 << std::endl;
}
ただし識別子の最初に1文字目に次の範囲の文字(結合文字)は使用できないとのこと。
0300-036F 1DC0-1DFF 20D0-20FF FE20-FE2F
5.10.2のところが理解できないなあ。。
特定の文脈において次の4つの識別子は特別な意味を持つとのこと。
audit axiom final override
この後の文章がうまく訳せない。。
When referred to in the grammar, these identifiers are used explicity rather than using the identifier grammar production.
文法中で参照されるとき、これらの識別子は文法生成の識別子を使用するのではなく明示的に使用されます??
ここですわ。。
Unless otherwise specified, any ambiguity as to whether a given identifier has a special meaning is resolved to interpret the token as a regular identifier.
特に明記しない限り、与えられた識別子が特別の意味を持つかどうかのあいまいさは、通常の識別子解析で解決される。
この4つの識別子「audit・axiom・final・ override」はいわゆる「キーワード」ではないということなのかな。。
overrideを例にとると、このメンバ関数はオーバーライドですよということを明確に示すためにあるということか。指定しなれば解析時に判定されるということかな。。
GLSLのプリプロセスを実装するためにC++の規格案を読んでるだけなのでまああいまいな理解でもいうのだが。
override/finalとか使えるようになってるんですな。。
違うか。。記述次第では意味を持たないケースもあるということかな。。文脈によって意味を持つということなので、キーワードとは別にしてるということかな。。
5.10.3.1は2つのアンダースコアを含む識別子と1つのアンダースコアで始まり、続く文字が大文字の識別子は実装のために予約されているとのこと。
5.10.3.2 さらに1つのアンダースコアで始まる識別子はグローバル名前空間のために予約されているのかあ。。
そしてようやく「5.11 Keywords」ですな。。
キーワードはとりあえず飛ばすか。識別子として予約されていると。後はアトリビュート中は除くと書いてあるな。。
「5.12 Operators and punctuators」もまあいいかな。注目すべきはプリプロセス前にトークン分割されるということですわな。#ifディレクティブとかでは定数式中で評価されるものもあるからな。。
さて次は「5.13Literals」かあ。ここはボリュームあるな。。
リテラルは7種類あるのですな。。
integer-literal
character-literal
floating-literal
string-literal
boolean-literal
pointer-literal
user-defined-literal
「5.13.2 Integer literals」もまあ理解できる。
こういう記法も可能なのですな。位取りか。。すごい。。
int \u3042 = 1'000'000;//位取り
int い = 0b0000'0001;//4ビット単位で区切ってみる
Table 7を見ると「l/L」サフィックスはlong以上の長さを表すということなんだなあ。「ll/LL」はlong longを表すようだけど。サフィックスなしはint/long int/long long intのいずれかであるということ。
あれだなあ。オレオレ言語は
・GLSLのスーパーセット
・C++のサブセット
みたいなものにしたいなあ。リテラルはC++のでいいわ。。
ただビルトイン型のビット長はrustのように仕様できちっと決めておきたいな。文字のエンコードはUTF-8を標準としたいね。
C++の規格書(仕様書)はESの仕様書に比べてかなり読みやすい気がする。あくまで「気がする」レベルだけど。
サフィックスのあいまいさは歴史的な経緯でこうなってるような気もするな。。
さて「5.13.3 Character literals」を読むか。。
文字リテラルというのはこうなってる。
character-literal:
encoding-prefixopt ’ c-char-sequence ’
encoding-prefix: one of
u8 u U L
「u8」プリフィクスが光っとりますな。。文字リテラルは1文字をあらわすんだけど、結合文字のためにシーケンスになってるのかな?
あ、そうか。マルチバイト文字か。。
u8に関してはちょっと残念なことがかいてあるな。。
The value of a UTF-8 character literal is equal to its ISO/IEC 10646 code point value, provided that the code point value is representable with a single UTF-8 code unit .
うむむ。。
If the value is not representable with a single UTF-8 code unit, the program is ill-formed. A UTF-8 character literal containing multiple c-chars is ill-formed.
コードポイントが1バイトで表現できる文字に限ると。マルチバイト文字は不正だと。。
C++にはmulticharacter literalなるものがあるとのこと。
規格案に書いてあった。
A multicharacter literal, or an ordinary character literal containing a single c-char not representable in the execution character set, is conditionally-supported, has type int, and has an implementation-defined value.
@cpp_akira さん。教えていただきありがとうございました。
この
character-literal:
encoding-prefixopt ’ c-char-sequence ’
encoding-prefix:
one of
u8 u U L
c-char-sequence:
c-char c-char-sequence c-char
このc-char-sequenceのところが不思議なのであった。。
基本的なところだけど、文字リテラルがシングルクォート、文字列リテラルがダブルクォートとC++では明確に定義されている。JSはどっちでもというか、文字リテラルにあたるものがないよな。。
エスケープシーケンスは3種類かあ。。
escape-sequence:
simple-escape-sequence
octal-escape-sequence
hexadecimal-escape-sequence
まあこれは知っとるなあ。というか\?ってなんだ???
simple-escape-sequence: one of
\’ \" \? \\
\a \b \f \n \r \t \v
これはほとんど使ったことないよなあ。。
octal-escape-sequence:
\ octal-digit
\ octal-digit octal-digit
\ octal-digit octal-digit octal-digit
これはまあ使ったことあるかな。。
hexadecimal-escape-sequence:
\x hexadecimal-digit
hexadecimal-escape-sequence hexadecimal-digit
ただこれ左再帰ということは任意の長さなんだなあ。
\x001111fddfffffffffffffffffffffffffffffffffffffffffeeee
とかも一応OKなんだろうか。。
5.13.3.8に書いてあるな。\xは任意の長さであると。
There is no limit to the number of digits in a hexadecimal sequence.
対して8進のほうはmax3桁までであると。
The escape \ooo consists of the backslash followed by one, two, or three octal digits that are taken to specify the value of the desired character.
前後するけど、5.13.3.2 には普通の文字リテラル「ordinary character literal」の定義とmulticharacter literalの定義が書いてある。
「ordinary character literal」はchar型を持つ「execution character set」で表現される一文字もc-charを含む文字リテラルということである。'0'はchar型で0x30の値を持ってるということですわな。。
でまあ1文字より多くの「ordinary character literal」含むリテラルを「multicharacter literal」であると定義している。型はintで実装定義であることは教えてもらった通り。なぜこれが規格案に入ってるのかちょっとググってみようかな。。
あ、ordinary character literalはプリフィクスはつかないんだな。
5.13.3.3はu8プリフィクスの説明。ここがちょっと使用上気になるところ。u8プリフィクスをつけるとこの文字リテラルはutf-8である。ただしバイト長が1byteのものに限定されてるんだなあ。。
再掲になるけどこの部分ですよ。
The value of a UTF-8 character literal is equal to its ISO/IEC 10646 code point value, provided that the code point value is representable with a single UTF-8 code unit (that is, provided it is in the C0 Controls and Basic Latin Unicode block).
ん、ここはちょっと私読み違えてる?code pointとcode unit の違いってなんだったっけ?
code point ... 文字につけられた番号
code unit ... code pointを符号化するときに使う一単位。utf-8だと1バイトになるよな。。
utf-32だと1コードポイント=1コードユニットになるのですな。
あかん。またUNICODEの沼に入ろうとしている。。
コードポイントは結合文字も含むので、コードポイントがかならずしも1文字を表すわけではないんですな。
multicharacter literalを見て思い出すのはFourCCコードですな。チャンクですわ。。
IFFか。。懐かしいな。。
なにげにFourCC ググったら、MSのページで使ってるじゃないの。multicharacter literal。。
DWORD fccYUY2 = '2YUY';
このマクロが懐かしい。。
DWORD fccYUY2 = MAKEFOURCC('Y','U','Y','2');
5.13.3.3に戻るけど、u8文字リテラルはutf-8だがコードユニットが1、つまりサイズが1バイトのものしか入れることができないということですわな。。
そしてmulticharacter literalはFourCCの記述用として使えるという。。
今のところは文字リテラルというのは1文字が入る器であってほしいなあと思うなあ。。無印リテラルや過去の互換性を維持するものはしょうがないにしても、u8リテラルはマルチバイトで1文字を表す仕様のほうがいいのではないかと。。
しかし文字リテラルってなんなんだろう。不思議なやつだ。。
1文字を表すという意味では不足しているし、かといって文字リテラルが文字の1文字を表すと明確に定義されているわけでもないしなあ。それが確実に保証されてるのはASCIIの部分だけだということか。。
5.13.3.3を読むとASCII文字だけで生活できる国はお得だなあと思うな。。
さて、5.13.3.4は「u」プリフィクスである。これはchar16_tの型を持つ文字リテラルであることを示す。
u’x’
日本語は「ローマ字」というものもあるから、これのみで生活すればASCII優位の恩恵にあずかることも可能かもとちょっと思ったが。ありえないか。それは。
5.13.3.4はUNICODEコードポイントの16ビットコードユニットを格納するための文字リテラルである。コードポイントをすべてカバーするにはサロゲート・ペアも使わないといけないんだけど、残念ながらこれも1文字で表すものに限られる。それ以外はill-formedである。
5.13.3.5は「U」プリフィクスである。これはchar32_tの型を持つ。コードユニットは32ビットである。つまりこのプリフィクスはすべてのUNICODEコードポイントを表すことができる。しかしながら結合文字というのがあり、複数のコードポイントで表す文字はこのリテラルに格納することは不正となる。

ななき@nanaki14
さっくり自分で書いたGLSL置くとこ作りました
とりあえず作って出そうって気持ちだったのでデザインとかアニメーション皆無ですが気が向いたらがんばります。
shader-practice.netlify.com https://t.co/NWG79cnnbj
S.F.@SFPGMR
@cpp_akira ありがとうございます。そのような仕様があるのですね。文字1つ分の仕様なのにBNFではシーケンスになってて謎でした。

Hideyuki Tanaka@tanakh
Intelは4004が50周年だったっけ?
S.F.@SFPGMR
二重思考か。。
Ryou Ezoe(江添 亮)さんのツイート: "奨学金と謳いつつ実態は借金であることを理解するにはダブルシンクを理解する必要がある。ダブルシンクとは2つの矛盾する事実が同時に存在しうるという概念である。ダブルシンクの理解にはダブルシンクが必要だ。党は常に正しい。"

中国最新情報(xChina)@xChina4
豆腐をめっちゃ細かく切るプロ https://t.co/CBj2wnAfAY
S.F.@SFPGMR
休み明けの初日の出勤はさすがに疲れたなあ。電車もなぜか混雑するし。。
S.F.@SFPGMR
さて私がすでに1000回は聴いてるであろう「BEHIND THE MASK」ですが。

この曲はSEIKOのCM用に作られた坂本さんの曲がベースとなっているとのこと。この曲を聴きたいがためにUC-YMOも買いました。。

この曲ってマイケルジャクソンがカバーしようとしたことでも有名だよなあ。こういのあるところからするとレコーディングまでしたのかな。。

このアレンジで最初に出たのは以下の方のようなんだよな。。

さらにこれをエリック・クラプトンがカバーしたりとか。
ちなみにこれも買ってしまいました。。

これをさらに坂本さんがセルフカバーするという。面白いよね。

このアレンジを聴いたのは確かメディア・バーン・ライブの時のやつだったと思うんだよな。やっぱりロックなんだなあ。この曲は。。と思った。
この曲は好きすぎて、自分でソフトシンセでコピーして再現しようと頑張ったが、このレベルで力尽きました。。
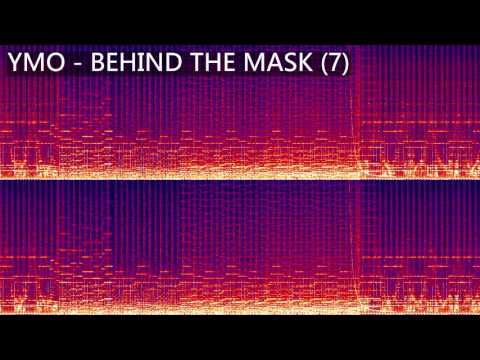
まだ道半ばの出来といったところで力尽きるという、いつもの私のパターンですが。。
トラックごとに音が聴けるというので2-3年前にGIGA CAPSULEも中古で買ったりもしたなあ。。 https://t.co/Qc4DzLjC5O

これは私が死ぬまで保有し続けるつもりの実物でございます。
ただ残念なことにトラックの音声ファイルは音質がかなり悪い。さらに悪いことに私のWin10環境では再生できない。というかShockwaveのアプリが動かんだけですけどね。
ただライディーンのコード弾きの部分のスコアを拾うのにはとても役に立ったけどね。。
YMOマニアとしては「ソリッド・ステイト・サバイバー」のマルチトラックデータが欲しいところではありますが。。
S.F.@SFPGMR
スマフォに触れた時点で数学の恩恵を受けているんだけどなあ。電化製品もそうだよねえ。。それ以外にもある。今日の文明生活の一端を数学が支えているというリスペクトは忘れないでほしいなあ。。
という私も数学は幼少期で理解不能になったクチなのですが。三角関数やベクトルは必要性が社会人になってわかってあわてて勉強したクチなのですが。すべての仕事において必要だというわけではないのですが。
成人になるまでの学習というのは、初期の段階では幅広くいろいろなものを学ぶのがよいのかなあと思う。成人になった時の自分のイメージを明確化できてる人はいるけど、そういうひとは少数派だと思うからね。それぞれの可能性を知る上でも幅広く学ぶことは必要なんじゃないかなと。
ある学問が苦手かどうかで方向性が見えてくるものもあるし。とはいえ学問も導く人の出来・不出来や性格の一致・不一致など純粋な学問以外のことで苦手意識が芽生えてしまう可能性もあるよなあ。。
そういう雑音みたいなものを排除して純粋に学問の良さを知ること自体、現代社会では難しいことなのかもしれないなあ。。
S.F.@SFPGMR
その通りですね。。
Hideyuki Tanakaさんのツイート: "てか数学だけクッソ初歩的なやつを逐一不要だ不要だと攻撃する勢力あるんだけどなんで数学だけ目の敵にされるんだ?数学は敵じゃないよ(´・_・`)"
S.F.@SFPGMR
TELEXで一番最初に聴いたのがこの曲なのですが。
「Dance To The Music」

で後になってこの曲はSly & The Family Stoneのカバーだということを知るのですが。

アナログシンセではどうしてもドラムの音が貧弱になってしまう。まああのような複雑なノイズ(複雑なノイズって。。)を作るのって無理があるんだよね。なので初期のYMOなんかもドラムは生なんだよね。高橋ユキヒロさんも確か生ドラムが一番って言ってたしな。。
だけどその貧弱な音に深めのリバーブとかゲートエコーとかけて厚み(というのかな)を出すテクで頑張ってた方々も一方でいるわけで。KRAFTWERKなどはわざとその貧弱な音を前面に出して特徴的なサウンドとしてた。ような気がする。
TELEXはアナログ・シンセのドラムで頑張ってるんだよな。。

ああ。「いい音圧」といったほうがいいのかも。
YMOの「ソリッド・ステイト・サバイバー」も生ドラム全開なのだが、生ドラム臭さを消すためのエフェクトをあえてかけて音をテクノっぽくしてるところがまたいいのですな。コンプかけたりと、極端なイコライジングとかノイズ・ゲートでリリースをカットしたりとか。。
ただキックだけはかなり近い音がシンセで作れるから、キャスタリアとかビハインド・ザ・マスクはキックがシンセなんですな。これがまた他の曲と毛色が異なる音になってて興味ぶかいのですが。。
Linnドラムの登場でドラムもまたリアルな音で自動演奏できるようになるわけですが。後期のYMOはいたるところで使いまくってるよね。。
このBrainwashっていう曲もドラムがいい音してると思うんだよね。。

ジョルジオ・モロダーの初期ものはキックが生で、スネアがシンセという組み合わせだったりする。面白いなあ。。

一聴してわかるジョルジオ・モロダーの特徴的な音づくりとアレンジ。。

そのジョルジオ・モロダーものちには生ドラムに戻るのですが。。

KRAFTWERKの初期のころはドラムの音作りはシンセなんだけど、自作っぽいパッドで生演奏してるんだよね。たしかに初期のアルバムとか聴くとリズムがちょっと揺れてたりしてるんだよな。
KRAFTWERKのドラムの1つの極みに達したと勝手に思ってるアルバムが「Europe Express」だと思ってたりする。
そして次のアルバムではスネアがパーカッシブになってたりする。これはアルバムのコンセプトに音色を寄せたんだと思ってるんだよね。

「コンピュータ・ワールド」では「ナンバーズ」という曲でさらにドラムがおかしな音になったりする。当時としては相当えげつない音だと思うんだけどね。。
Ultravoxも古くからリズムマシンを使ったりしてるよね。リズムマシンな曲も結構ある。

「thin wall」もそうだよな。。

UltravoxとYMOの類似性で一番有名なのは「Passionate Reply」だよな。

Linnが登場するあたりの時代で、シンセ主体のポップ・ミュージックのリズム音がガラッと変わったのはほんとそうだよなあ。Yazooなんかもう全然違うもんな。1枚目と2枚目のリズムの音色が。1枚目は808で、2枚目はドラム・マシン(どこのメーカーかは不明)。
これが1枚目の曲「Don't Go」
これが2枚目の曲「Nobody's diary」
ヴィンス・クラークがいたころのDepeche Modeもリズム・ボックス全開ですなあ。。

アナログ・シンセベースのリズム・マシンは消滅するかと思ってたけど、その独特な音色ゆえにいまだに使われることになるとは夢にも思わなかったなあ。
現代にまで残ることに関しては、日本のシンセメーカーの果たした役割もまた大きいよな。特にローランドですわ。808と909がなかったらどうなっていたことか。。ああ、909はハイブリッドですが。。
アナログ・リズムマシン→サンプリング・ドラム→アナログ・リズムマシンの再評価→共存という進み方をしたんだよな。。
ちょっと話を戻すと、坂本龍一さんの初期アルバムもシンセによるリズム音作りにこだわった感じがするんだな。例えば「plastic bamboo」とか。。
このスネアの音ですよ。これ。
Riot In Lagosのリズムもすごい音色だと思う。これが初期坂本サウンドで最高のリズムではないだろうか。。

「War Head」もリズムはシンセですわな。

まあしかしYMOのお三方ですとやっぱり細野さんのリズムマシンのアレンジが最高はないかと。。

生音のキックと808のキックのタイミングがぴったり合ってるところがさらに良くて。初期のYMOだとシンセのキックと生ドラムのキックはちょっと頭がずれてたりするよな。東風とかね。
技術の進歩ですわな。。
Pure Jamの808のハットもいいよねえ。。なんか生っぽい。。

この細野さんの曲のリズムとか当時ちょっととびぬけてた気もするのですよ。。

当時日本のミュージシャンでこんな音作りしている人はたぶんいなかったと思う。
ハービーハンコックあたりにも通じるところがあるよなあ。。


アタリショック(ハメコミ合成研究中w@goegoezzz
ソフトベンダーTAKERU
ブラザー工業 https://t.co/QrzCGhH07t
S.F.@SFPGMR
Windows + VC++で遊んでた時はUnicode = wchar_t使うという感じだったよな。確かに。wchar_tは2バイトで、1単位でUnicodeの任意の一文字を表すことができると。でもサロゲート・ペアを知るとそれは無理筋なんだよな。
wchar_t自体UTF-16だと言えるのはWindowsの世界だけなんだなあ。。そもそもwchar_tはエンコードや文字コードが規定されてないということか。。
UTF-32であっても、結合文字だったっけ?があるからもはや固定長で文字を表すということ自体が幻想であるのですな。。
そういえばWindowsではTCHARなるマクロがあったよなあ。。Unicodeビルド/マルチバイトビルドを切り替えできるように文字列はすべてこのマクロで指定しておくと。_T("ABCDEF")なんちゅうリテラル用のマクロもあったなあ。。
C++11には、char16_t/char32_tなる型があるのか。バイト長は決めたけど、相変わらずエンコード方式の規定はないのですな。
と思ったらUTF-8だけはエンコードが保証されてるのかいな。。
・UTF-8文字列リテラル
u8"このリテラルはUTF-8でエンコードされることが保証される";
UTF-8文字を表す型であるchar8_tはC++20で採用なのですな。。
「ワイド文字はなぜいけてないか」がよくわかるなあ。。
・「char8_tによせて」
char8_tによせて - なるせにっき
C++標準化委員会、ついに文字とは何かを理解する: char8_tという記事が話題だってので、つらつらと書いてみました。 「グリフ」について グリフ(glyph)という言葉の定義をめぐって でも触れられていますが、「グリフ」という言葉が「字体」を指すのか「字形」を指すのかってのは議論がありますね。文字コードの文脈では普通「字形」の意味だとして話を進めることが多いように思います。 CJK統合漢字について Wikipediaの記事にまとまっていますが、実際に推進していたのは中国みたいですね。うまくやればあんまり問題なかったんでしょうが、あんまりうまく行かなかったんですが、それでも国ごとにその国の過…
char8_tはUTF-8であることが保証されるから、まあライブラリも作りやすくなるんだろうな。文字列を長さを求めるやつとかね。。長さ=コードポイント数であってほしいからね。。
Unicodeの複雑さの1つに合成済み文字というのがあってですな。
これに対して結合文字ちゅうのもあってですな。。
例えば「ぱ」という文字はUnicodeでは2通りあるんですな
結合文字を使う:「は」+「゜」... "\u306F\u309A"
合成済み文字を使う:「ぱ」 ... "\u3071"
実際に実行してみるとこんな感じ。。
なので同じ文字だけど比較すると偽と出る場合があるので、比較する場合は正規化を行わないといけないんだよなあ。。
でこの正規化にはUnicodeで定められた形式(NFD/NFC/NFKD/NFKC)があるんだよな。。
もうUnicodeに触れるのはやめておこう。。肩凝ってきたわ。。
ああ、正準等価と互換等価ちゅうのもあるんだよなあ。。等価性だけとってみても面倒なんですわ。。
tech.albert2005.co.jp/501/
S.F.@SFPGMR
@syntaxerrors72 よろしくお願いいたします。
ゲイラカイトはまだ現役なのですね!しかし思い返すと勉強はほぼせず、外で遊びまくった小学生時代だったような気がします。。
S.F.@SFPGMR
小学生のころこれ買ってもらってほぼ毎日遊んでたな。。冬の遊びの定番でしたわ。。
これ用のタコ糸ってのがあった。ナイロンかなんかでできてて、それ以前の凧用とは明らかに違うしろもので、それ自体珍しかった。これを2-3本繋いで上げたりしたんだな。でまあ途中で切れたりするんだけど回収が大変だった。電柱にこれがよく引っかかってたりもしたよな。。
そのタコ糸ってのが棒にきれいに巻かれていて、幾何学模様のような感じなんだけど、飛ばすとそれが紐解かれていく様を見てちょっと感動したりとか。凧もそうだけど紐に興味をそそられるという。。
風が弱くても上がるんだけど、逆に風が強いとちょっとコントロールが難しいし、落ちるときの衝撃が強くて道路に激突して壊れたりもした記憶もあるなあ。何回か買いなおしたような記憶も。。

WebAssemblyWeekly@WasmWeekly
Doom 3 running in the browser using Emscripten / WebAssembly continuation-labs.com/d3wasm/ https://t.co/1HtX6OgJ2w
S.F.@SFPGMR
1/1-2は熱海・伊豆にいた。
これは1/2の日の出。。 https://t.co/OfUwtbPqTg

大室山はちょっとすごかったんだよなあ。これは下からとったんだけど、すり鉢を伏せたような形をしててね。。山焼きをしてるから木が生えてないんだよな。なので山の形がはっきりわかるんだよね。。 https://t.co/uM8F6QL7uF

頂上まではリフトで登るんだけど、周りに高い山がないので見晴らしが最高に良い。 https://t.co/kos55ECnSQ

火口の周りをぐるっと1周できる。周囲は1キロくらいあるみたい。 https://t.co/BhEJZGEVQ8


遠くから見るとこんな形をしてるらしいね。。この写真はWikipediaのものですが。。
これは元旦の初日の「入り」でございます。。それでは今年もよろしくお願いします。。 https://t.co/gGE9O6ZMDR

しかし謎なのは大室山の火口にあるアーチェリー場なんだよな。。どういういきさつであそこでアーチェリーをすることになったのか。。 https://t.co/EOU8tlXUAm

S.F.@SFPGMR
何故か風船が!!!!と思って調べたら、誕生日だと風船が飛ぶらしい。。 https://t.co/OmXFNqxuUq

S.F.@SFPGMR
今年こそオレオレ言語が完成するだろうか。。
S.F.@SFPGMR
このベースの音とベースラインですわなあ。。ハウス。。

ベースメント・ボーイズが絡んだやつも好んで聴きましたわ。このバスドラとベースが特徴的ですわな。。

S.F.@SFPGMR
Observableというサービスがなかなか興味深い。。
S.F.@SFPGMR
まじか。。この時代にカセットテープでソフトウェアの新製品が販売されるとは。。
BEEPさんのツイート: "第1回BEEPレトロホビーゲームプログラムコンテストの8ビット部門金賞作品が遂に販売開始です〜!P6ユーザーの方は要チェックですね。作品はこちらでご紹介しておりますhttps://t.co/FhywtahHjY… "